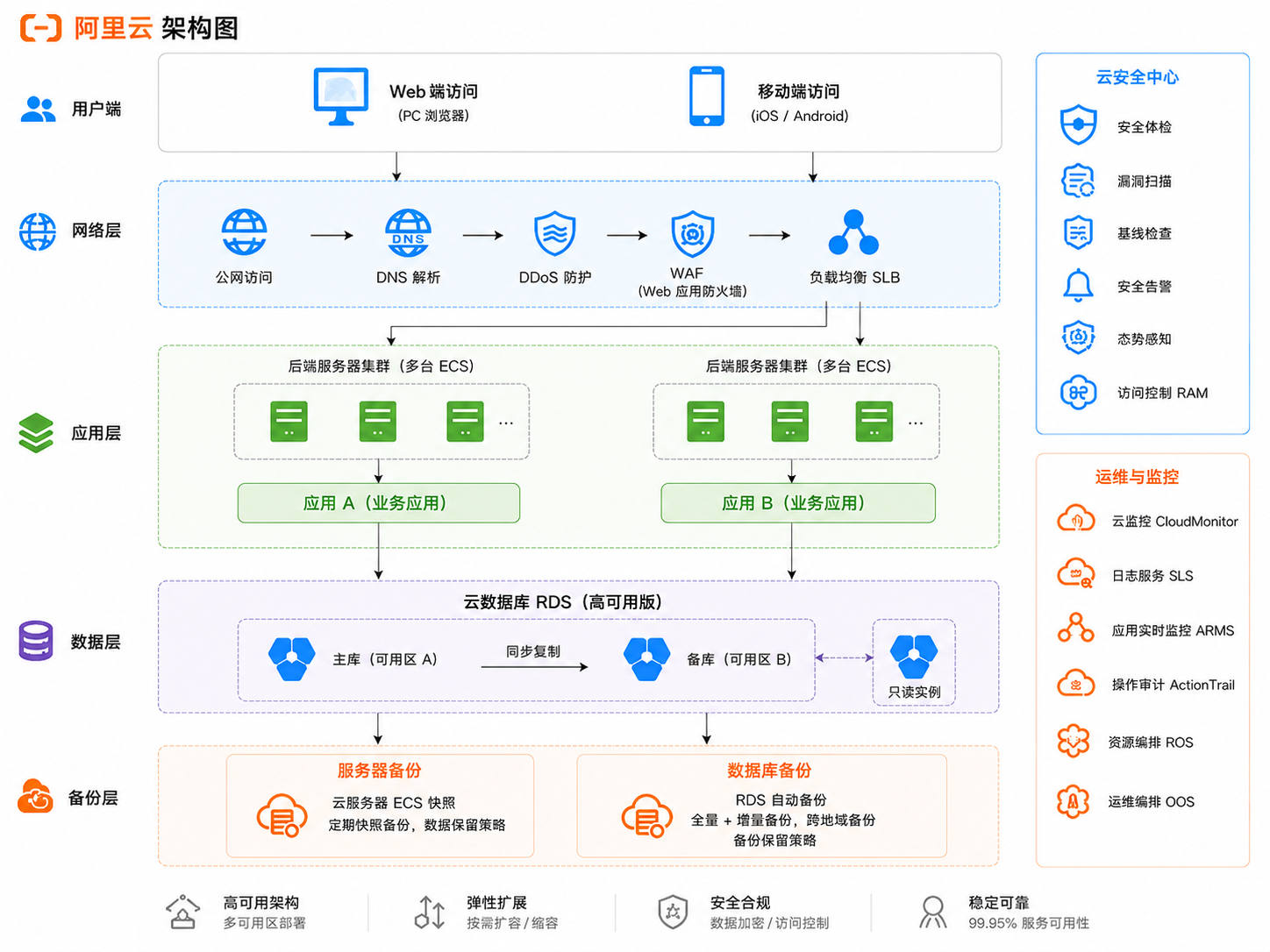
项目概览
这是一家国内商业地产及泛家居连锁龙头企业,员工上万人,旗下业务涵盖城市综合体、家居连锁门店和线上商城。2023 年下半年,云璨信息技术为其完成了 ERP 系统与官网从本地机房到阿里云的整体迁移——服务器通过 SMC(服务器迁移中心)迁移至 ECS,数据库通过 DTS 完成全量加增量同步,割接业务中断窗口约 1 小时,数据完整无丢失,回滚预案完整备就但未触发。
本文完整还原这个项目从现状评估到割接上线的全过程。


项目背景与痛点
机房资源触顶,扩容要等六周
双十一前夕,线上商城在大促预热期第一天开始响应变慢。IT 运维排查后发现,本地机房物理服务器 CPU 长时间跑在 85% 以上,存储剩余空间不足 15%。要扩容,需要走硬件采购流程——询价、审批、采购、到货、上架,整个周期至少六周,旺季等不了六周。
这不是第一次遇到这个问题,但每次的解法都是"撑过去"。撑过了这次大促,下次大促还会再来。
痛点一:计算与存储双双触顶,扩容周期拖不起
物理机的上限是固定的,业务增长却是连续的。每逢节假日或大促,IT 团队要提前数月做资源预留,但预留多了淡季大量闲置,预留少了旺季顶不住——这个矛盾在固定硬件架构下无解。
痛点二:运维团队规模小,多个系统长期被动响应
客户 IT 运维团队只有数人,却要同时负责 ERP、官网等系统的日常巡检、故障处理和版本升级。告警响应依赖个人经验,一旦核心成员休假或离职,整个运维体系就会出现空档。
痛点三:数据库无异地备份,容灾能力薄弱
ERP 数据库存放着集团多年的交易、库存和客户数据,但备份策略只有每日本地快照,保留周期 7 天。没有异地备份,没有跨可用区副本,也没有明确的 RTO / RPO 目标。如果机房断电或磁盘故障,没有人能回答"最快多久恢复、数据能恢复到什么时间点"。
痛点四:服务器安全状态不透明,异常无从感知
本地机房服务器没有统一的安全基线管理,也没有漏洞扫描和入侵检测机制。运营团队曾发现几次访问异常,但 IT 无法判断是正常波动还是真实风险,只能凭经验判断。本次迁移以云安全中心接管服务器安全状态的统一可视化为基础,Web 层进阶防护作为后续专项推进。
痛点五:硬件重资产,IT 预算结构被动
每次扩容都是一次性采购,折旧周期三到五年,买了之后规格调不了,卖不掉,只能用到折旧完毕。这种重资产结构让 IT 部门的预算编制极为被动。
核心矛盾不是 IT 能力不足,而是固定基础设施的弹性跟不上业务规模的动态变化。
方案选型:为什么迁公有云,而不是继续扩容
这个项目在方案阶段讨论过两个方向:一是继续扩充本地机房硬件,二是整体迁移至公有云。
本地扩容 vs 公有云迁移
选择本地扩容,采购一批服务器能撑两三年,但弹性问题、容灾问题依然存在,下一轮资源触顶还会到来。公有云解决的不只是容量,而是整个基础设施的运营模式:从重资产一次性采购,转向按需付费使用资源。
对比维度 | 本地机房扩容 | 阿里云迁移 |
|---|---|---|
扩容速度 | 硬件采购 4–8 周 | 弹性伸缩,分钟级扩缩 |
容灾能力 | 本地快照,无异地备份 | 跨可用区 + 跨区域备份 |
安全基线 | 无统一管理,依赖本地防火墙 | 云安全中心统一管控,安全状态可视 |
成本结构 | 一次性重资产,固定折旧 | 按需付费,淡季自动缩容 |
运维压力 | 完全依赖内部 IT | 可托管专业代运维团队 |
本次建设周期 | — | 8 周完成评估至割接 |
SMC 迁移服务器,DTS 迁移数据库
为什么服务器和数据库分开迁移:
服务器选用 SMC(服务器迁移中心),可将物理服务器直接转化为 ECS 镜像,无需重装操作系统和应用,对现有系统侵入性最低。数据库单独通过 DTS(数据传输服务)做全量 + 增量同步,而不是随服务器一起整机迁移。
原因是 ERP 数据库体量较大(主表接近 200GB),如果整机迁移,全量传输期间必须停止写入,停机时间无法控制。DTS 支持在业务不中断的情况下完成全量同步,割接时只需等待增量延迟归零,将业务中断时间压缩到分钟级。
迁移过程:八周分阶段执行
第一阶段(第 1–2 周):现状评估与迁移规划
云璨工程师进驻客户机房,采集各服务器的 CPU / 内存 / 存储规格与实际负载曲线、网络拓扑、数据库规格和数据量、各系统间的调用依赖关系。
评估阶段发现两个需要提前处理的问题:
硬编码内网 IP 依赖: ERP 应用配置文件中直接写入了本地机房服务器 IP,迁移后 IP 变化会导致服务间调用失败,需在上线前逐一梳理替换
数据库体量超出整机迁移可接受范围: ERP 主业务数据库单表接近 200GB,停机导出导入耗时数小时,割接窗口无法接受,需改用 DTS 在线增量同步
评估完成后输出迁移规划文档,确定三批迁移顺序:
第一批: OA 和内部工具系统(容错率高,影响面小)
第二批: ERP 核心业务系统
第三批: 线上商城(面向消费者,最后迁移以保证充分验证)
第二阶段(第 3–4 周):云上环境搭建
ECS 选型与弹性伸缩配置
根据各系统历史负载基线,在阿里云华东 2(上海)选定 ECS 规格。核心业务系统(ERP、商城)配置冗余实例,接入弹性伸缩组,CPU 使用率超过 70% 自动触发扩容。
RDS 高可用配置
部署 RDS MySQL 主备双节点,开启自动备份(每日一次,保留 7 天),配置跨可用区只读实例用于报表查询分流,减轻主库压力。
负载均衡配置
为线上商城和 ERP 配置负载均衡,后端挂载多台 ECS 实例。健康检查设置 HTTP 探测,每 5 秒一次,连续 3 次失败自动将故障节点从负载均衡池中摘除。
安全组与网络配置
安全组按最小权限原则逐条配置:仅开放业务必要端口(Web 服务 80/443,数据库仅允许应用层内网访问,SSH 仅限运维跳板机 IP),禁止默认全放通规则,数据库安全组与应用安全组隔离。
这一阶段出现一个典型问题:OA 系统在云上首次启动后,邮件通知功能无法发出。排查发现是安全组未开放 SMTP 出站方向,补加出站规则后恢复。这类应用层端口依赖在迁移前的系统文档中通常没有记录,需要在实际联调时逐一确认。
云安全中心接入
各 ECS 实例统一接入云安全中心,开启基础版漏洞检测和服务器安全状态监控,确保上云后安全基线可见、异常可感知。
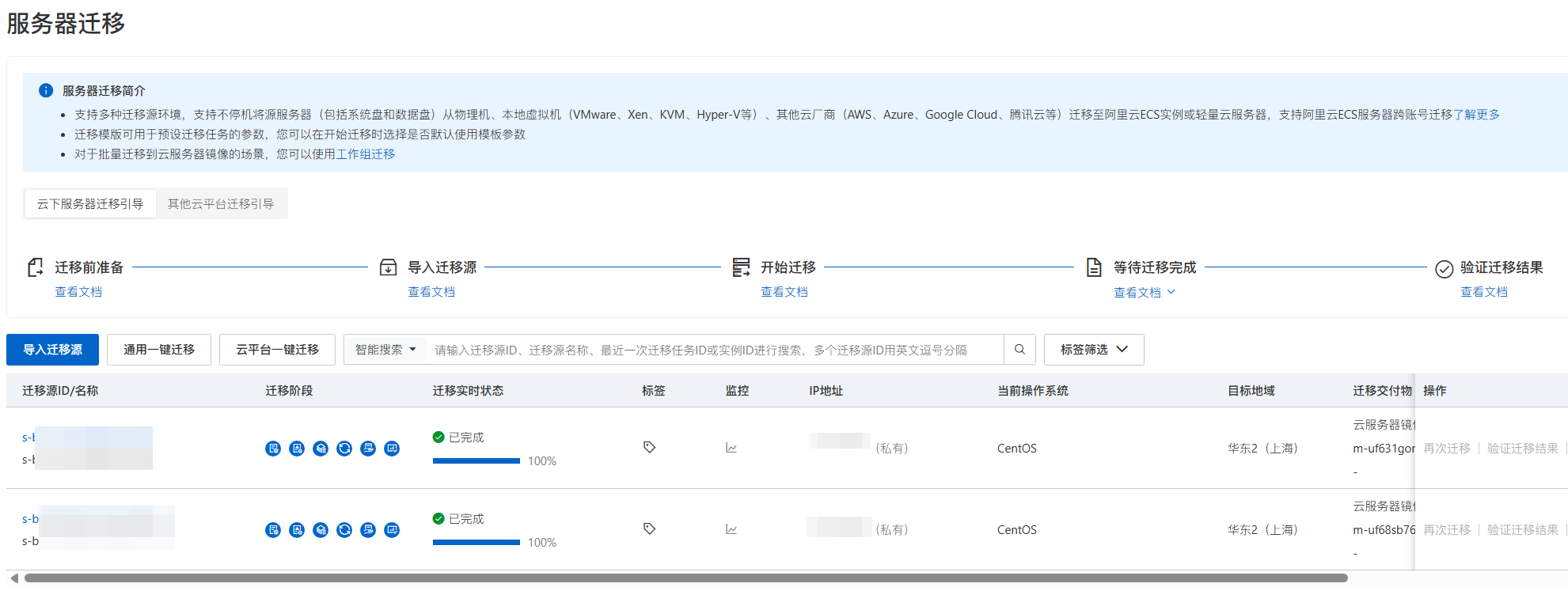
第三阶段(第 5–6 周):服务器迁移与数据库同步
SMC 服务器迁移
在各物理服务器上安装 SMC 客户端 Agent,连接至 SMC 控制台后系统自动生成迁移任务,将源服务器的操作系统、应用程序和数据全量复制到 ECS,期间源服务器正常运行,业务不中断。
迁移过程中几个需要注意的操作细节:
迁移任务开始前,先对源服务器做一次完整快照,作为基础回滚保障
迁移完成后不立即停止源服务器,先在云上 ECS 启动并完成功能验证,确认无误后再执行切换
各系统配置文件中硬编码的内网 IP 在 ECS 启动前统一替换为云上内网地址或内部域名
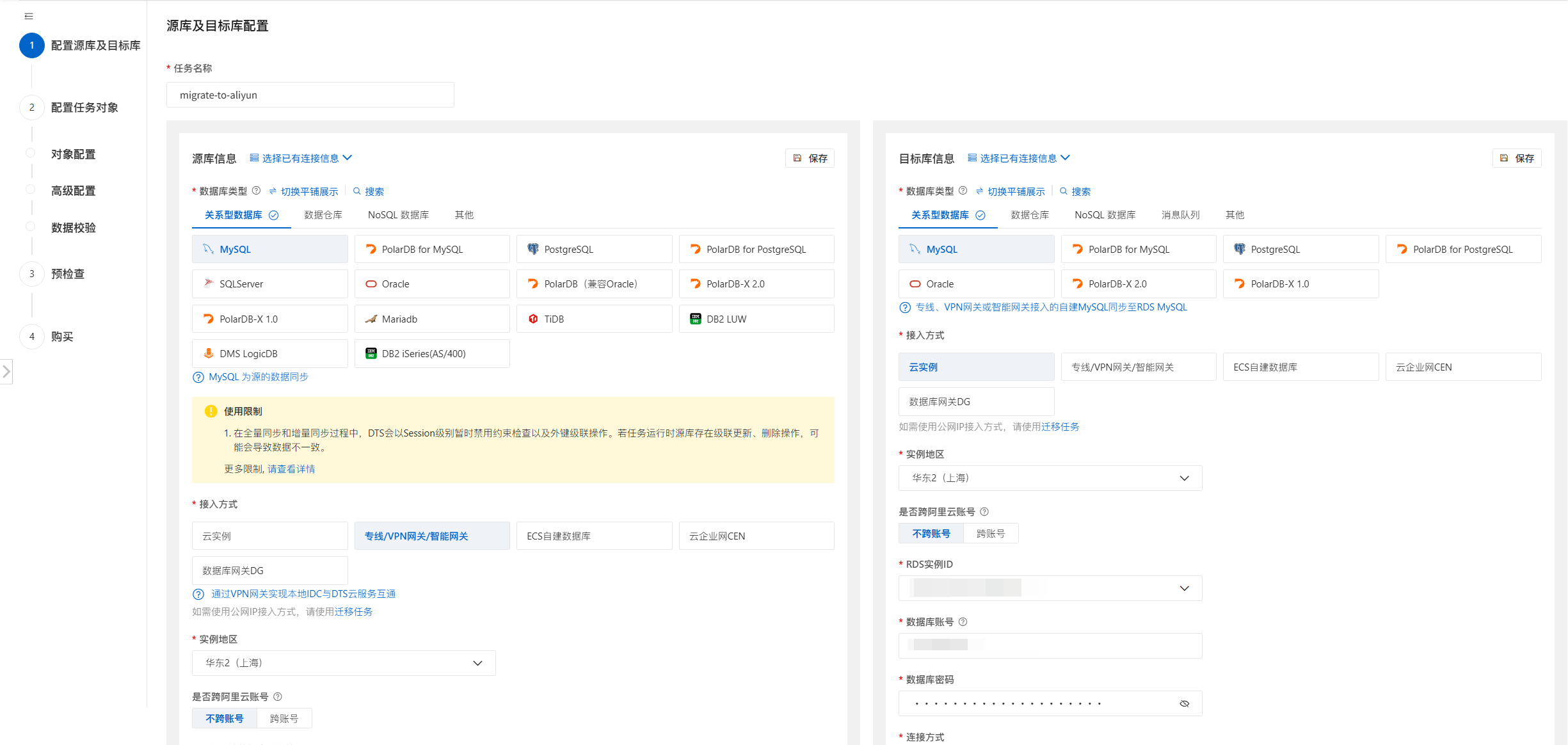
DTS 数据库迁移
ERP 数据库通过 DTS 分三个步骤完成迁移:
全量同步: DTS 将本地 MySQL 全量数据同步至云上 RDS,期间本地数据库正常读写,全量同步约需 6 小时(200GB 数据量)
增量同步: 全量完成后,DTS 自动切换为基于 binlog 的增量实时同步,持续同步全量阶段产生的新数据,同步延迟稳定在 3 秒以内
持续监控: 云璨工程师持续监控 DTS 控制台,关注延迟指标、错误率和数据一致性

并行运行与功能核查
云上环境就绪后,与本地机房并行运行两周。云璨协调客户核心业务人员在云上环境执行标准操作流程,覆盖 ERP 订单录入、库存查询、报表导出等高频场景,与本地环境结果逐项比对。两周内共发现并修复 3 处配置差异,均为应用层参数问题,无数据层问题。
第四阶段(第 7 周):割接与切换
割接选在周五晚间 23:30 开始,提前一周对外发布维护公告,说明可能出现约 1 小时的访问中断。选择这个时间点的考虑是:流量处于低谷,工程师状态尚可,即使出现需要回滚的情况,处理时间充裕。
割接前准备(割接前 72 小时内完成)
本地机房环境冻结,不允许任何变更操作
回滚预案文档确认,各负责人分工和联系方式同步
云上环境逐项核查:ECS 实例状态、RDS 连接、负载均衡健康检查、安全组规则
割接执行流程
时间 | 操作 | 目的 | 负责方 |
|---|---|---|---|
23:00 | 云上环境最终核查,回滚预案就位确认 | 确认退路清晰 | 云璨 |
23:30 | 停止本地应用服务,关闭业务写入入口 | 防止割接期间产生新数据 | 云璨 + 客户 IT |
23:35 | 确认 DTS 增量同步延迟归零,核查数据一致性 | 确认云上数据与本地一致 | 云璨 |
23:45 | 停止 DTS 同步任务,锁定数据库 | 建立明确的数据截止点 | 云璨 |
23:50 | 启动云上 ECS 应用服务 | 云上环境进入就绪状态 | 云璨 |
23:55 | 逐条核查安全组规则,验证各端口连通性 | 确认应用层网络联通正常 | 云璨 |
00:05 | 确认负载均衡后端节点健康检查全部通过 | 确认负载均衡正常分发流量 | 云璨 |
00:10 | 修改 DNS 解析,指向阿里云 EIP | 将流量切向云上 | 云璨 |
00:15 | 从公网访问各域名,确认解析已生效 | 确认 DNS 切换完成 | 云璨 + 客户 IT |
00:20 | 核心业务功能核查:登录、查询、提交订单 | 确认业务层面可用 | 客户 IT |
00:30 | 功能核查通过,割接完成,进入持续监控 | — | 云璨 |
01:30 | 持续监控 1 小时,各项指标正常,割接收尾 | — | 云璨 |
业务中断窗口:23:30–00:30,约 1 小时(本地应用停止写入至功能核查通过)。
安全组联调说明
割接时逐条验证了各服务的端口连通性:应用服务器到数据库的 3306 端口、应用对外的 80/443、运维跳板机的 SSH 22 端口。这个步骤预留了约 10 分钟,目的是在正式切流量前确认网络层没有问题,避免 DNS 切换后才发现端口不通。
回滚预案(完整备就,本次未触发)
割接前,云璨与客户 IT 共同确认回滚预案,写入割接操作手册。
触发条件(再割接窗口无法完全处理以下问题即执行回滚):
核心页面响应时间持续超过 5 秒,超过 3 分钟未恢复
RDS 连接异常或数据库主备切换失败
负载均衡后端节点健康检查全部不通过
业务功能核查发现数据不一致
回滚步骤:
DNS 解析切回本地机房 IP
重新启动本地机房应用服务(本地环境在割接后 72 小时内保持冻结状态,随时可启动)
如有必要,通过 DTS 将割接期间云上产生的少量数据回流至本地数据库
通知客户 IT 和业务部门,业务切回本地环境运行
本次割接顺利完成,回滚预案未触发。事后与客户 IT 负责人复盘时,对方提到:知道有明确的回滚步骤和触发条件,是整个割接过程中最让人踏实的事——不是因为预期会失败,而是出现意外时有清晰的处置路径,而不是临时决策。
第五阶段(第 8 周):运维交接
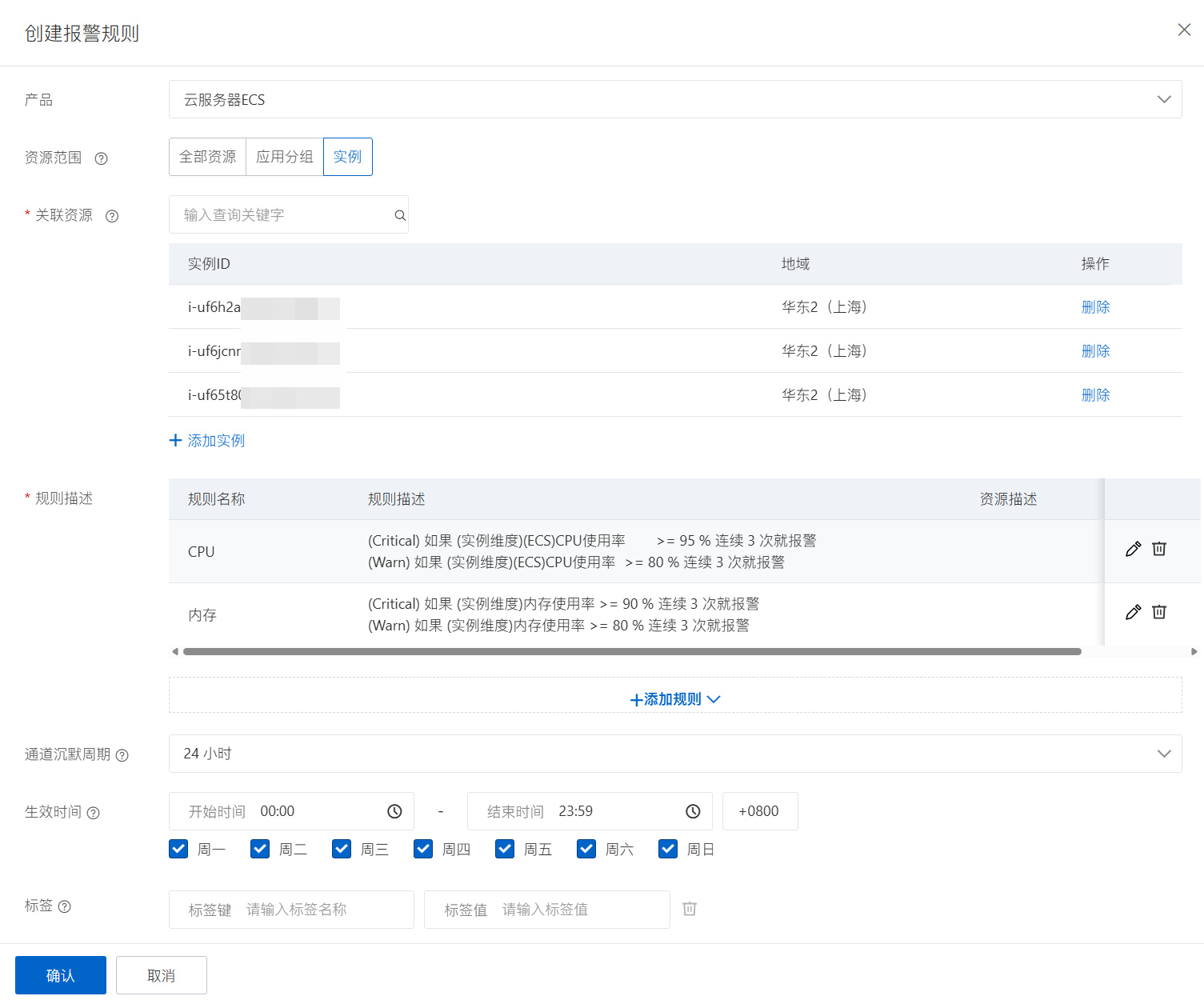
监控告警配置
配置云监控告警规则,覆盖 CPU、内存、磁盘、带宽、数据库连接数、负载均衡后端异常节点数等核心指标,告警同时推送至云璨运维团队和客户 IT 负责人。
上线后的变化
大促期间资源弹性
迁移前: 大促前两个月开始规划资源,向采购部门提需求,审批通过后等硬件到货,手动上架配置,整个过程至少 6 周。大促结束后资源大量闲置,利用率不足 20%。
迁移后: 弹性伸缩组根据 CPU 使用率自动触发。首个双十一大促峰值为平日 3.2 倍,弹性伸缩自动扩出 4 台实例,全程无需人工干预,商城平均响应时间稳定在 800ms 以内,未出现超时。
故障告警响应
迁移前: IT 运维靠人工巡检或业务人员反馈发现问题,从问题发生到 IT 开始排查,通常已过去 30 分钟到 1 小时。
迁移后: 云监控 + 云璨 7×24 监控覆盖,指标异常 1 分钟内触发告警,运维团队 15 分钟内介入处理。客户 IT 团队每周收到巡检报告,了解系统运行状态。
数据备份与恢复能力
迁移前: 每日本地快照,保留 7 天。恢复只能还原到快照时间点,操作手动,无法精确到分钟级。
迁移后: RDS 自动备份 + binlog 连续日志,支持精确到秒的时间点恢复(PITR)。配置跨区域备份后,RPO 从"最多丢失 24 小时数据"优化为"不超过 5 秒"。
迁移经验整理
硬编码 IP 是迁移评估中最容易被忽略的问题
应用配置文件里写死的内网 IP,通常没有文档记录,只能逐一检查每套系统的配置文件才能发现。建议在评估阶段专门做一轮 IP 依赖梳理,在并行验证阶段完成替换验证,不要留到割接当天处理。
数据库体量超过 50GB,建议单独用 DTS 处理
随服务器整机迁移数据库,全量传输期间必须停止写入,停机时间无法预估。DTS 全量 + 增量方案可以在业务不中断的情况下完成数据同步,割接时只需等待增量延迟归零,将停机时间压缩到分钟级。
安全组联调应在并行验证阶段完成,不要留到割接当天
安全组按最小权限配置后,各端口连通性需要实际测试确认:应用到数据库、应用对外服务、运维 SSH 访问,每一条都要联通。这个工作如果留到割接当天才做,一旦发现问题处理时间压力很大。建议在并行验证阶段完成,割接当天只做最终确认。
回滚预案要在割接前明确,包括触发条件和执行步骤
完整的回滚预案——触发条件、执行步骤、责任人——让割接过程更可控。本次未触发回滚,但预案的存在让整个团队在割接过程中有清晰的判断依据,遇到问题时不需要临时讨论怎么处理。
适用场景参考
以下情况可以参考本案例的迁移路径:
本地机房资源接近上限,扩容周期或成本无法接受: 固定硬件每次扩容都是一个采购项目,公有云弹性扩缩在分钟级完成
业务存在明显淡旺季或促销峰值: 峰值资源与日常资源落差大,按需付费比固定硬件更经济
IT 运维团队规模小,同时需要支撑多个业务系统: 基础设施托管给专业代运维,内部 IT 可以从日常巡检中释放
对迁移过程的业务中断时间有要求: SMC + DTS 组合可以将割接窗口控制在分钟级
不一定需要一次性迁移全部系统。可以从容错率高的内部系统开始,验证流程和工具链后,再逐步迁移核心业务系统。
了解更多
云璨信息技术(上海)有限公司是阿里云授权合作伙伴,专注为企业提供上云规划、迁移实施与代运维服务。如需了解适合您企业的迁移方案,欢迎联系我们。
